Project brief
You have been working with the local government to help direct policy decisions. They are concerned about an increase in traffic accidents and think they may be able to make changes to reduce the severity of accidents that do occur. But they don’t know what the most important features are for defining the difference between severity of an accident. They would like you to investigate the data and see if it would be possible to find the factors that are most important. Based on these factors, what changes should be made to reduce the severity of accidents that do occur?
Basic EDA
I decided to go with the ‘Ambulance’ column as an indicator of the severity of an accident. There are some other columns, but they contain categories like ‘suspected” or ’possible injury’. Here I assume that if there is an ambulance, the case is serious enough to investigate the reasons.
From looking at the number of crashes per year I can’t say that we see an increase in traffic accidents.
Monthly trend resembles the average yearly temperature for North Carolina. This makes sense as warmer temperature means more people using bikes.
Here we can observe not only the rise in bike crashes during the day but also the change in proportions of how many people need an ambulance.
Looks like in the 25-29 group people are less likely to get into accidents and then chances get higher as one gets older.
Most crashes happen while bikers ride along the traffic. This could mean a poorly developed biking paths system which is not surprising when we talk about US cities.
Here we can see that indeed most crashes happen while bikers ride along the traffic and not using bike paths. Quick google search showed that even bike paths that do exist are very questionable quality. Probably digging into this could reduce accidents even more.
Here we can see that more populous cities have more crashes which can be explained by the amount of people using bikes there. But most crashes actually happen in rural areas that lack bike infrastructure. This might be another indicator that fixing biking infrastructure can actually increase the situation.
MODELING
Training/Test Split
bikes$ambulance <- as.factor(bikes$ambulance)
#SPLIT
set.seed(666)
# Create the balanced data split
bikes_split <- initial_split(bikes,
prop = .75,
strata = ambulance)
# Extract the training and test set
bikes_train <- training(bikes_split)
bikes_test <- testing(bikes_split)Random Forest
This is a go-to model for classification problems. Perfect balance between complexity and accuracy.
Plot Variable Importance
# Specify a random forest
spec <- rand_forest() %>%
set_mode("classification") %>%
set_engine('ranger', importance = 'impurity')
# Train the forest
model <- spec %>%
fit(ambulance ~.,
data = bikes_train)
# Plot the variable importance
vip::vip(model, aesthetics =list(fill = '#31a7eb')) + theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(),
panel.background = element_blank(), axis.line = element_line(colour = "black"))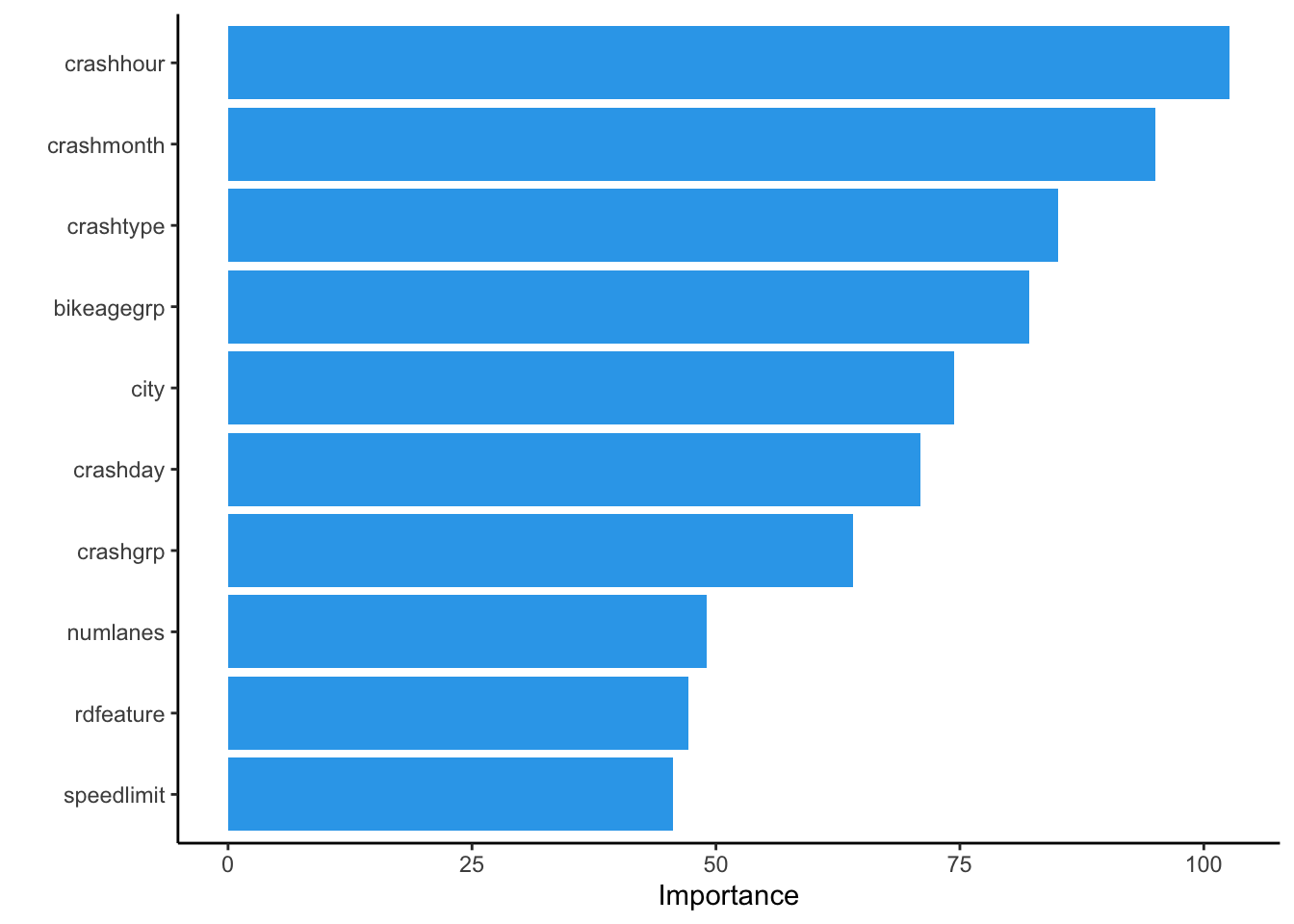
Feature importance helps us to identify features that are having the most impact on outcome variables. Even though it’s a good indicator for the analysis, we have to be careful while interpreting these results. More domain knowledge is needed. Here we see that the time when a crash happened has the most effect on the severity of an accident.
Evaluating accuracy
# Generate predictions
predictions <- predict(model,
new_data = bikes_test, type = 'class')
# Add the true outcomes
predictions_combined <- predictions %>%
mutate(true_class = bikes_test$ambulance)
# The confusion matrix
bikes_matrix <- conf_mat(data = predictions_combined,
estimate = .pred_class,
truth = true_class)
# Get accuracy of the model
acc_auto <- accuracy(predictions_combined,
estimate = .pred_class,
truth = true_class)
acc_auto$.estimate## [1] 0.7116345Current accuracy is 0.7116345, which can be improved by tuning and using boosted-trees. But I would not be expecting a big increase in model performance since we are trying to predict real-life events involving humans and there’s no machine learning algorithm that can predict human behaviour (yet).